
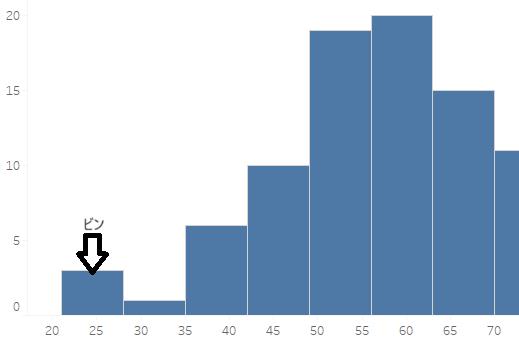
さまざまな分析業務を行う中で、表やグラフを眺めている皆さん。「ヒストグラム」という言葉を耳にしたことがあるのではないでしょうか?
「ヒストグラムってなんだ?」と思われたそこのあなた。下のキャプチャをご覧ください。このようなグラフを一度は目にしたことがあるはずです。ヒストグラムについての詳しい説明はこちらを読んでみてください。
(https://www.stat.go.jp/naruhodo/4_graph/shokyu/histogram.html)
今回はこのヒストグラムを生成するために、ビンの設定を自動で行うための処理を実装した際の苦労話を書きました。
今回の開発は、複数のカラムに対してビンを動的に設定したいという要望を元に実施しました。この処理のメリットとして、ヒストグラムをデータ更新に合わせることができます。また、複数のカラムに対して、ループ処理の中で子ループを回すこともできるようになります。
前提条件
- ヒストグラムのビンにラベル付けをしたい
- 中間テーブル(一時書き出しを行うテーブルを利用する)を使用する
目次
- 設計
- 実装
- せっかくなのでAIにも書かせてみた
- まとめ
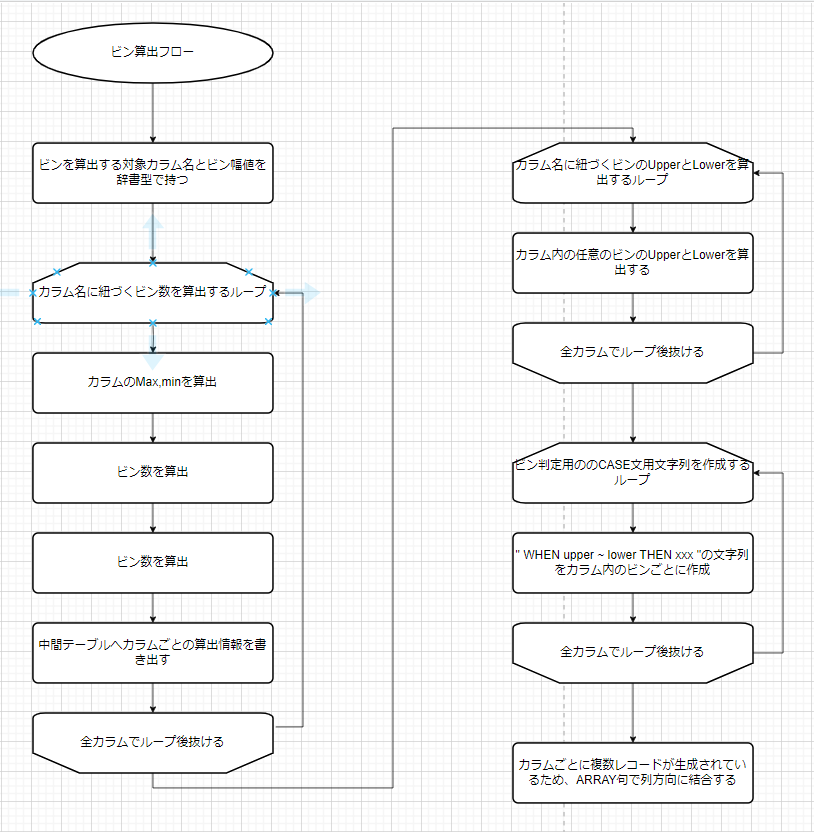
設計
- 各カラムの最大値、最小値を取得し、値域を算出する
- カラム毎に値域をビン(定数)で割り切れるか判定し、ビン数を算出する
- ビン数分ループ処理を実行する
- 実行する処理内容:ビンのUpperとlowerを算出し、ビン情報中間テーブルに書き出す
- ビン情報中間テーブルに書き出されたレコードをもとに、ラベルに使用する文字列(CASE文)をCASE文中間テーブルに書き出す
- CASE文をARRAY_AGG, ARRAY_JOINしてCASE文を1レコードにまとめる
- ラベリング用SQLに文字列を利用して完了!
実装
この記事ではカラム単位の値域算出の工程はスキップします。(Max - minするだけです!) ビン幅(bin_width)は固定値のため、値域によっては余りが出る可能性があります。そこで、値域が割り切れるかの判定が必要になります。
Sample Code : bin_num.sql
SELECT
column_name
, column_max
, column_min
, column_width
, bin_width
, CASE
WHEN (column_width % bin_width) >= 0 THEN CAST(CEILING(column_width / bin_width) AS DOUBLE)
ELSE CAST(CEILING(column_width / bin_width) AS DOUBLE)
END AS bin_num
FROM table
次に、ビンの数だけループ処理を行います。 SQLの算出結果をdigdag内で呼び出すには”store_last_results: true”を設定する必要があります。ここが最初の山場でした。col_Aでa回ループ、col_bでb回ループ、、、、、col_nでn回ループという処理をしたいのですが、store_last_resultsはtd>が呼び出されると上書きされてしまうのです。digdag初心者の私は調べました。きっと優秀な先人たちが戦いの記録を残してくれているはずと。 はい。いらっしゃいました。for_each>:内でループ処理を呼び出すことで解決できるとのこと。素晴らしいですね。
# td結果を保存するためのグループ
+task_data_keep:
for_each>:
column_name: ["${td.last_results.column_name}"]
column_max: ["${td.last_results.column_max}"]
column_min: ["${td.last_results.column_min}"]
column_width: ["${td.last_results.column_width}"]
bin_width: ["${td.last_results.bin_width}"]
bin_num: ["${td.last_results.bin_num}"]
_do:
+task_in_column_loop_group1:
loop>: ${bin_num}
_do:
# 任意のビンのmax, minを算出する
+echo:
echo>: "${td.last_results.bin_num}"
+task_bin_lower_upper:
td>: sql/bin/_l2_bin_lower_upper.sql
store_last_results: true
insert_into: table_name
-- {i}番目のビンのlower, upperを算出
SELECT
'${column_name}' AS column_name
, '${column_max}' AS column_max
, '${column_min}' AS column_min
, '${column_width}' AS column_width
, '${bin_width}' AS bin_width
, '${bin_num}' AS bin_num
, (CAST('${column_min}' AS DOUBLE) + (CAST('${bin_width}' AS DOUBLE) * ${i})) AS bin_lower
, (CAST('${column_min}' AS DOUBLE) + (CAST('${bin_width}' AS DOUBLE) * (${i} + 1)) - 1.0) AS bin_upper
この処理によって画像のようなビン情報中間テーブルが作成できます。

各ビンのupperとlowerが算出できましたね。
さて、カラムごとのビン情報を算出 ラベル付け用SQLに用いるCASE文を作成するために、厄介な場合を行わなければなりません。ロジックを説明していきます。
- bin_lower = column_max
- bin_lower < column_max AND column_max < bin_upper
- bin_upper < column_max
- それ以外
上記の場合分けを行いました。ビン幅固定のため、Max値と最大値域のビン幅の位置関係が重要です。2の条件によって最大値域はbin_upper = column_maxとなります。
このままではCASE文には投入できませんね。String型の文字列に結合しなければなりません。
WITH t1 AS (
SELECT
column_name
, column_max
, column_min
, bin_width
, bin_upper
, bin_lower
FROM xxx_bins_middle_subtable
GROUP BY
column_name
, column_max
, column_min
, bin_width
, bin_upper
, bin_lower
)
, t2 AS (
SELECT
column_name
, CASE
-- bin_lower = column_max
WHEN bin_lower = CAST(column_max AS DOUBLE) THEN CONCAT('WHEN ', column_name, ' = ', CAST(bin_lower AS VARCHAR), ' THEN ', '''', CAST(bin_lower AS VARCHAR), ''' ')
-- bin_lower < column_max AND column_max < bin_upper
WHEN bin_lower < CAST(column_max AS DOUBLE) AND bin_upper > CAST(column_max AS DOUBLE) THEN CONCAT('WHEN ', column_name, ' BETWEEN ', CAST(bin_lower AS VARCHAR), ' AND ', CAST(column_max AS VARCHAR), ' THEN ', '''', CAST(bin_lower AS VARCHAR), '~', CAST(column_max AS VARCHAR), ''' ')
-- bin_upper < column_max
WHEN bin_upper < CAST(column_max AS DOUBLE) THEN CONCAT('WHEN ', column_name, ' BETWEEN ', CAST(bin_lower AS VARCHAR), ' AND ', CAST(bin_upper AS VARCHAR), ' THEN ', '''', CAST(bin_lower AS VARCHAR), '~', CAST(bin_upper AS VARCHAR), ''' ')
ELSE CONCAT('WHEN ', column_name, ' = 0.0 THEN ', '''', CAST(column_min AS VARCHAR), '~', CAST((CAST(column_min AS DOUBLE) + CAST(bin_width AS DOUBLE) - 1) AS VARCHAR), '''')
END AS case_condition
FROM
t1
)
SELECT
column_name
, ARRAY_JOIN(ARRAY_AGG(case_condition), ' ') AS case_condition
FROM t2
GROUP BY column_name
縦方向の結合に有効な関数がARRAY_AGG関数です。
うん。綺麗に連結されていますね。
あとは、このケース分をクエリに格納すれば完成です。
SELECT
cstm_no
, CASE
${case_condition}
END AS ${column_name}_bin
FROM
table
今回はdigdagとSQLを使用することに限定しましたが、Pythonを使えばもっとスッキリ書けただろうな。。。
せっかくなのでAIにも書かせてみた
私が普段から大変お世話になっているAIに上記条件を達成するためのコードを生成させてみました。
<プロンプト1>
- 各カラムの最大値、最小値を取得し、値域を算出する
- カラム毎に値域をビン(定数)で割り切れるか判定し、ビン数を算出する
- ビン数分ループ処理を実行する
- 実行する処理内容:ビンのUpperとlowerを算出し、ビン情報中間テーブルに書き出す
- ビン情報中間テーブルに書き出されたレコードをもとに、ラベルに使用する文字列(CASE文)をCASE文中間テーブルに書き出す
- CASE文をARRAY_AGG, ARRAY_JOINしてCASE文を1レコードにまとめる
- ラベリング用SQLに文字列を利用して完了!
上の内容でpythonを書いてください
<結果1>
import numpy as np
import pandas as pd
# 画像に記載された処理フローを実装する関数
def calc_bin_and_case(df):
"""
各カラムの最大値、最小値を取得し、値域を算出
カラム毎に値域をビン(定数)で割り切れるか判定し、ビン数を算出
ビン数分ループ処理を実行
実行する処理内容:ビンのUpperとlowerを算出し、ビン情報中間テーブルに書き出す
ビン情報中間テーブルに書き出されたレコードをもとに、ラベルに使用する文字列(CASE文)をCASE文中間テーブルに書き出す
CASE文をARRAY_AGG, ARRAY_JOINしてCASE文を1レコードにまとめる
Args:
df: pandas DataFrame
Returns:
df_case: ラベルに使用するCASE文を格納したDataFrame
"""
# 各カラムの最大値、最小値を取得し、値域を算出
df_maxmin = df.agg(['max', 'min'])
df_maxmin['range'] = df_maxmin['max'] - df_maxmin['min']
# カラム毎に値域をビン(定数)で割り切れるか判定し、ビン数を算出
df_maxmin['bin_num'] = np.ceil(df_maxmin['range'] / BIN_WIDTH)
# ビン情報中間テーブル
df_bin_info = pd.DataFrame()
# ビン数分ループ処理を実行
for col in df.columns:
for bin_idx in range(df_maxmin.loc[col, 'bin_num']):
# ビンのUpperとlowerを算出
upper = df_maxmin.loc[col, 'min'] + bin_idx * BIN_WIDTH
lower = df_maxmin.loc[col, 'min'] + (bin_idx - 1) * BIN_WIDTH
# ビン情報中間テーブルに書き出す
df_bin_info = df_bin_info.append({
'col_name': col,
'bin_idx': bin_idx,
'upper': upper,
'lower': lower
}, ignore_index=True)
# ビン情報中間テーブルに書き出されたレコードをもとに、ラベルに使用する文字列(CASE文)をCASE文中間テーブルに書き出す
df_case = pd.DataFrame()
for col in df.columns:
case_str = ''
for bin_idx in range(df_maxmin.loc[col, 'bin_num']):
upper = df_bin_info.loc[df_bin_info['col_name'] == col, 'upper'].iloc[bin_idx]
lower = df_bin_info.loc[df_bin_info['col_name'] == col, 'lower'].iloc[bin_idx]
case_str += f"WHEN {col} BETWEEN {lower} AND {upper} THEN '{bin_idx}'"
# CASE文中間テーブルに書き出す
df_case = df_case.append({
'col_name': col,
'case_str': case_str
}, ignore_index=True)
# CASE文をARRAY_AGG, ARRAY_JOINしてCASE文を1レコードにまとめる
df_case['case_str'] = df_case['case_str'].apply(lambda x: f"CASE {x} END")
df_case = df_case.assign(
case_str=df_case['case_str'].str.join(' '))
return df_case
# 設定
BIN_WIDTH = 10 # ビン幅
# 処理実行
df_case = calc_bin_and_case(df.copy())
やっぱり変数で持たせる方が圧倒的に早いですよね。これを数秒で生成できるなんてすごいなと改めて感じました。
<プロンプト2>
## 中間テーブルを使用せず、変数でデータを持つように修正してください<結果2>
import numpy as np
import pandas as pd
# 画像に記載された処理フローを実装する関数
def calc_bin_and_case(df):
"""
各カラムの最大値、最小値を取得し、値域を算出
カラム毎に値域をビン(定数)で割り切れるか判定し、ビン数を算出
ビン数分ループ処理を実行
実行する処理内容:ビンのUpperとlowerを算出し、ビン情報変数に書き出す
ビン情報変数に書き出された情報をもとに、ラベルに使用する文字列(CASE文)をCASE文変数に書き出す
CASE文を1レコードにまとめる
Args:
df: pandas DataFrame
Returns:
case_str: ラベルに使用するCASE文
"""
# 各カラムの最大値、最小値を取得し、値域を算出
df_maxmin = df.agg(['max', 'min'])
df_maxmin['range'] = df_maxmin['max'] - df_maxmin['min']
# カラム毎に値域をビン(定数)で割り切れるか判定し、ビン数を算出
df_maxmin['bin_num'] = np.ceil(df_maxmin['range'] / BIN_WIDTH)
# ビン情報変数
bin_info = {}
# ビン数分ループ処理を実行
for col in df.columns:
bin_info[col] = []
for bin_idx in range(df_maxmin.loc[col, 'bin_num']):
# ビンのUpperとlowerを算出
upper = df_maxmin.loc[col, 'min'] + bin_idx * BIN_WIDTH
lower = df_maxmin.loc[col, 'min'] + (bin_idx - 1) * BIN_WIDTH
# ビン情報変数に書き出す
bin_info[col].append({
'bin_idx': bin_idx,
'upper': upper,
'lower': lower
})
# ビン情報変数に書き出された情報をもとに、ラベルに使用する文字列(CASE文)をCASE文変数に書き出す
case_str = ''
for col in df.columns:
case_str_col = ''
for bin_info_item in bin_info[col]:
upper = bin_info_item['upper']
lower = bin_info_item['lower']
case_str_col += f"WHEN {col} BETWEEN {lower} AND {upper} THEN '{bin_info_item['bin_idx']}' "
case_str += f"CASE {case_str_col}END "
return case_str
# 設定
BIN_WIDTH = 10 # ビン幅
# 処理実行
case_str = calc_bin_and_case(df.copy())
上記コードでは、以下の変更を行いました。
・ビン情報中間テーブルとCASE文中間テーブルを廃止し、代わりにビン情報変数とCASE文変数を導入しました。
・ビン情報変数とCASE文変数はループ処理内で更新されます。
・処理結果は、ラベルに使用するCASE文として返されます。やっぱり変数で持たせる方が圧倒的に早いですよね。これを数秒で生成できるなんてすごいなと改めて感じました。
まとめ
- store_last_resultsがリセットされてしまうこと
- 閾値(ビンのupperとカラムの最大値の大小関係で場合分け)
- 列方向の結合方法
- AI無しでは僕はこれから先仕事できない気がする
このタスクを通じて上記4つのことを学びました。解決までの時間でみると1が特に重かったですね。
最後まで読んでいただきありがとうございました!
【参考資料】
Qiita記事(https://qiita.com/pilot/items/c0e9b7bce888fbbc70e1)
SQL Function(https://trino.io/docs/current/functions/array.html)